
Add a Custom Prompt
Prerequisites
Integrate a pre-built or custom LLM before creating a prompt. See LLM Integration.Steps
- Go to Generative AI Tools > Prompts Library.
- Click + New Prompt (top right).
-
Enter the Prompt Name, then select the Feature and Model.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=69ee5ca1bc4ee3968603e0805bd191fb)
-
The Configuration section (endpoint URL, auth, headers) is auto-populated from the model integration and is read-only.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=880cdee8a94541888ff3245ab1e9232a)
-
In the Request section, create a prompt or import an existing one.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=f0993fa32feafd212d07927eb9bd9a87)
-
Click Import from Prompts and Requests Library.
-
Select the Feature, Model, and Prompt. Hover and click Preview Prompt to review before importing.
You can interchange prompts between features.
- Click Confirm to import the prompt into the JSON body.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=89254af10bd4f4550efa7e3bf78a5a11)
-
Click Import from Prompts and Requests Library.
-
(Optional) Toggle Stream Response to enable streaming. Responses are sent incrementally in real time instead of waiting for the full response.
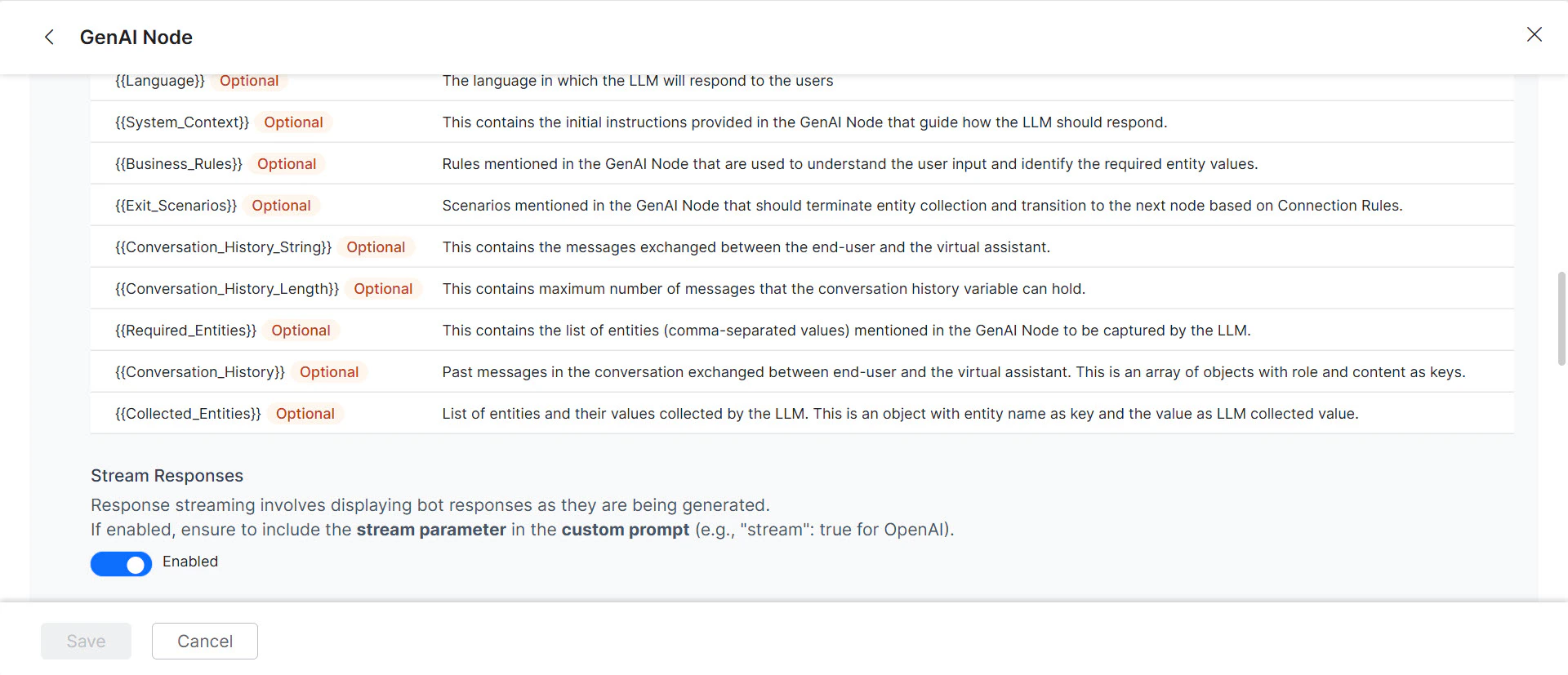
- Add
"stream": trueto the custom prompt when streaming is enabled. The saved prompt displays a “streaming” tag. - Enabling streaming disables the “Exit Scenario” field. Streaming applies only to Agent Node and Prompt Node features using OpenAI and Azure OpenAI models.
-
Fill in the Sample Context Values and click Test. If successful, the LLM response is displayed; otherwise an error appears.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=8187ccaad6e49e643c8d2a95a6e795bb)
-
Map the response key: In the JSON response, double-click the key that holds the relevant information (e.g.,
content). The Platform generates a Response Path for that location. Click Save.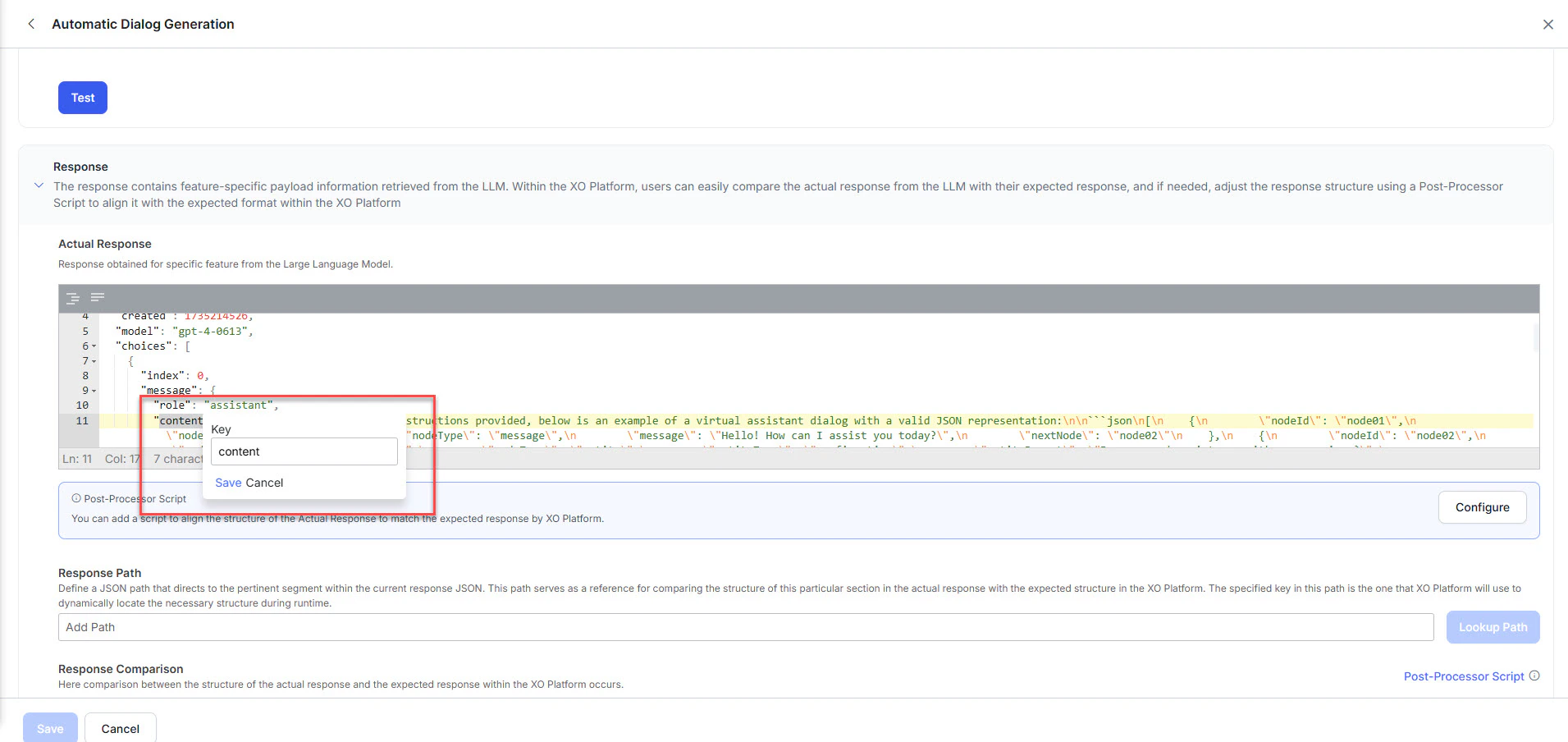
-
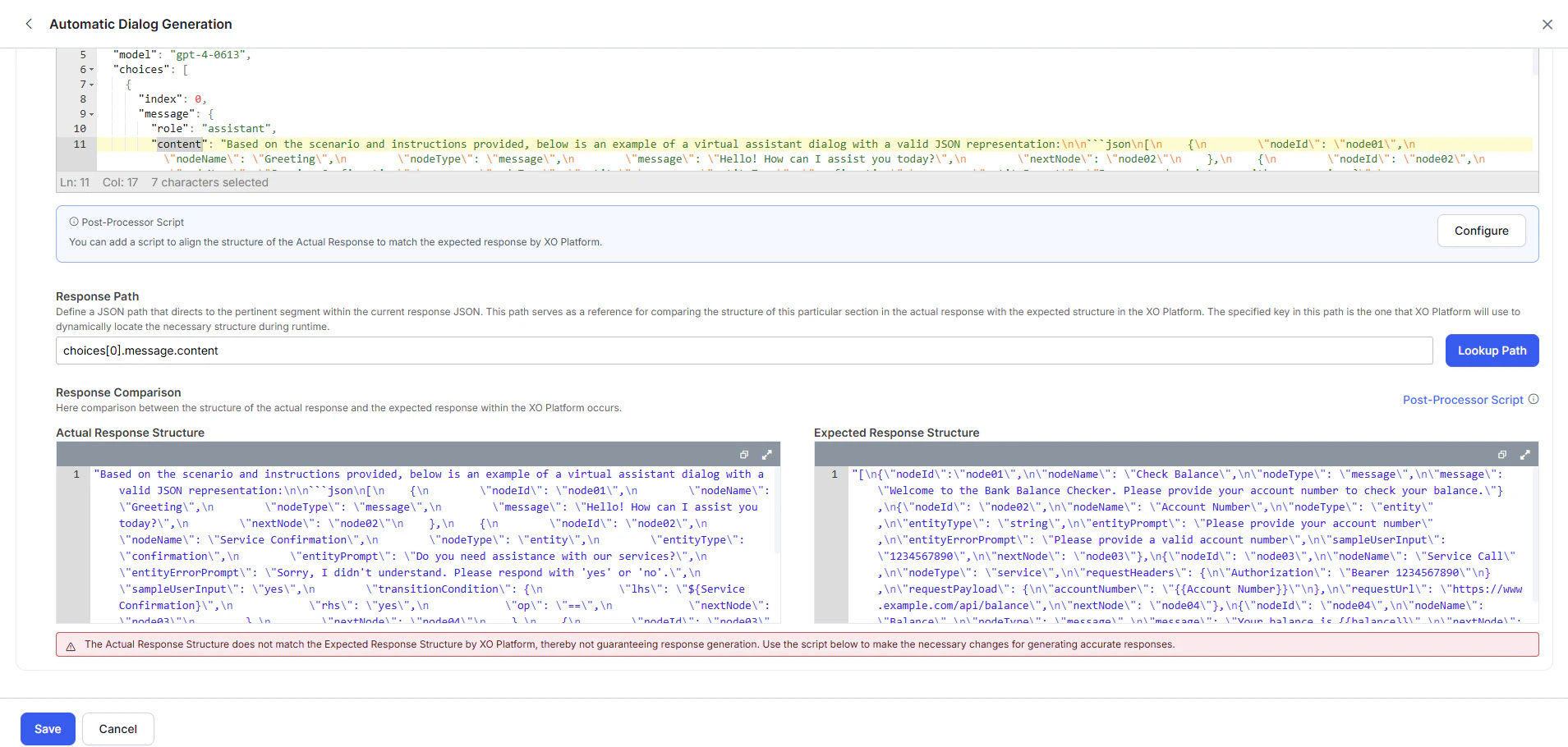
Click Lookup Path to validate the path.
-
Review the Actual Response and Expected Response:
-
Green (match): Click Save. Skip to step 12.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=ac2d26250b627a3a048718a4fd42c7a5)
-
Red (mismatch): Click Configure to open the Post Processor Script editor.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=b87d6bf8b73f22e8dfc9ee0c0390f033)
-
Enter the Post Processor Script and click Save & Test.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=9a1ed5f28268ae9efbe2359a961d4c6e)
-
Verify the result, then click Save. The responses turn green.
.png?fit=max&auto=format&n=o0iG_cZ6W1HNumoO&q=85&s=4ff388047e393ae07bd13ba3993760d4)
-
Enter the Post Processor Script and click Save & Test.
-
Green (match): Click Save. Skip to step 12.
-
(Optional) If Token Usage Limits are enabled for your custom model, map the token keys for accurate tracking:
- Request Tokens key:
usage.input_tokens - Response Tokens key:
usage.output_tokens
 Without this mapping, the Platform can’t calculate token consumption, which may lead to untracked usage and unexpected costs.
Without this mapping, the Platform can’t calculate token consumption, which may lead to untracked usage and unexpected costs. - Request Tokens key:
- Click Save. The prompt appears in the Prompts Library.